Integration Strategy
Operational Data orchestration via Hyperscalers & MuleSoft Anypoint iPaaS.
Data integration is the process of combining and transforming data from various sources and data domains to influence a business outcome. This typically deals with structured data from databases and text files using deterministic rules for batch and near-real-time use cases.
Data orchestration on the other hand, goes beyond data integration. It combines data discovery, data preparation, data integration, data processing, and enriched data connectivity across complex landscapes. This deals with semi/un/structured data from DB’s, transactional, object stores, streaming, messages, and no-sql systems using data enrichment, modeling operations for batch, near real time, lambda, workflow, and process automation.
Traditionally, these were handled by niche applications/platforms, but as paradigms shift, the distinction between them is becoming increasingly blurred (but still exists where it makes sense.)
Operational data is generated by an organization’s day-to-day operations (business events, objects ex: customer, inventory, and purchase data) supporting operational type business processes. Operational data may consist of real-time transactional data or batch data with a short history (3-6 months). OLTP systems such as relational databases were traditionally the primary choice, but with changing data schemes (multi structural data) and cloud capabilities, data lake storages such as AWS S3(and ecosystem services) are emerging to serve these use-cases, providing flexibility and extendibility while keeping costs low. This data has more real-time integration needs with ELT type workloads from case to case.
Analytical data is the result of historized operational data collected from multiple systems, over time and used to guide operational processes toward improvement. The goal is to gain knowledge that will help guide better day-to-day operations using data and analytics. This would necessitate large-scale data persistence and compute capabilities (from an infrastructural standpoint) to generate appropriate descriptive and prescriptive insights. ELT type data integration, processing.
The integration needs of operational and analytical data sourcing are nuanced(payload, frequency, transformation types, compute, visualizations), with many fundamental needs/capabilities in common(Data pipelines, Pipeline-as-a-Code). In some organizations there is distinction between who manages/owns operational and analytical data, integration. Although such a clear distinction from a data perspective is difficult to make because certain data assets can be used for both operational and analytical purposes, we will be able to differentiate integration and processing requirements for each. Operational data enables business events and execution, and it is reliant on both real-time and batch data. Before we dive deep let’s look at some integration patterns:
- Synchronous
- RPC(Remote procedure Calls)
- Rest Http
- SOAP
- Asynchronous
- Event driven
- Pub-Sub
- Streaming
- gRPC
- Batch
- File
- Direct DB access
- Virtualization
- B2B, SaaS
Many of the above integration patterns can be enabled by IPaaS platforms such as MuleSoft, but specific hyperscaler capabilities and hybrid use cases still have a place. Let’s use AWS services as an example.
Pattern of Functional-as-a-Service (FaaS) + API Gateway: AWS Lambda + AWS API Gateway proxied via MuleSoft is an excellent choice for certain workloads that require massive scale, parallel processing, and can leverage existing in-house and native AWS capabilities.
Cloud Storage: MuleSoft does not include a solution for long-term object storage. This is where AWS S3 shines as a long-lasting, scalable file system for object storage, which can be useful for complimenting MuleSoft capabilities. MuleSoft has developed an S3 connector, which is available in Exchange. These could be domain-specific data lakes that allow for orchestration.
Messaging: Even though Any point MQ is a good queue offering. Amazon SQS and SNS are still reliable services for AWS workloads. If data transport via the public internet is not preferred, we can use AWS network fabric for protection, latency, and scale. SQS, SNS integrate well with other AWS services (ex: serverless). MuleSoft has developed a SQS connector that can be found in Exchange.
Streaming and IoT: As IoT (consumer and industrial) needs grow, native IoT management and streaming capabilities are critical to meeting those needs. AWS IoT and Kinesis are required for real-time data collection, analysis, and streaming. These services are heavily leveraged today by Digital Manufacturing Cloud platform to enable smart factory use cases(supplementing operational systems), device management, etc.
Polyglot persistence: MuleSoft does not include any persistence capabilities beyond basic object storage. Polyglot persistence capabilities are required for digital native use cases that enable various business processes. Differentiating capabilities are provided by AWS DynamoDB for No-SQL, AWS RDS for relational, and AWS Neptune for graph-based data representations.
Heavy batch data processing: It is not uncommon for operational systems to rely on aggregated data from a batch workload to execute business. AWS Glue and EMR provide such processing capabilities, which can be interfaced with using MuleSoft.
Microservices: There is no need to justify the importance of microservices for building tailored business solutions in today’s day and age; services like AWS lambda, as well as container orchestration services like EKS, enable such workloads while still leveraging MuleSoft gateway fabric.
State Machine execution: Not all operational data processing follows a linear pattern. Some call for state machine execution, which executes a flow based on predefined business rules (static and dynamic). AWS step functions are an excellent choice for state machine executions because they can execute business rules by interacting with Mule and AWS native components orchestrating complex workflows.
CI/CD: MuleSoft workloads are not exempt from DevSecOps and CI/CD practices. By combining MuleSoft with the AWS DevOps offerings, AWS makes it simple to create and automate your integration pipeline.
Additional areas where hyperscaler-based data layers will be beneficial include:
- AWS S3 can enable file based SFTP workloads, which can then be supplemented with Mule API processes.
- Storage of historical data for some operational SaaS systems. (For example, OMP, our advanced planning system, lacks scalable persistence capabilities, but such data is required to perform historical root cause analysis and tune operational processes), AWS S3 can act as low-cost long-term datalakes, enabling such use cases.
- While data virtualization should be preferred over replication, some advanced processing of data requires it to be staged (cannot perform transformations on the fly), in those cases, AWS RDS and other services can be useful. (For example, the Talend-based Integration for Project Green Path performs advanced data transformations by staging it in AWS; a similar process is followed by the customer platform (subject to correction)).
- Vendor-neutral data provisioning (middleware) for SaaS (&other) platforms where DataOps (beyond mule capabilities) is performed in AWS, promoting modularity, portability, and loose coupling while minimizing vendor dependency. (For example, low-code platforms such as Appian, it is best to separate skin (UI/presentation/workflows) from flesh (DataOps).)
- Any applications that we sunset because of rationalization can benefit from cloud native storage for data staging.
- Although MuleSoft works well with structured data, we require hyperscaler capabilities to deal with semi/un/structured data orchestration.
- The network externality of cloud native services is too valuable to forego, given their widespread adoption by businesses (including ours) and the open source community. Mule, as a closed system, necessitates specialized knowledge.
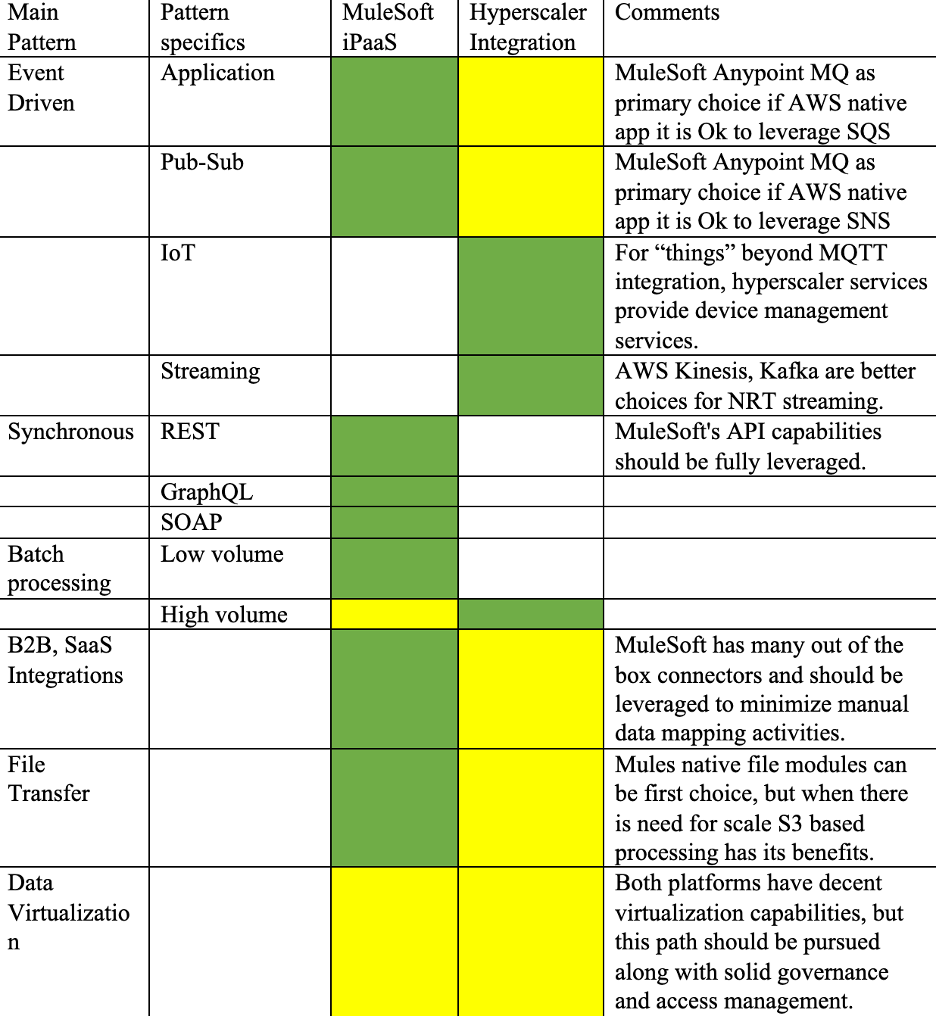
With the above analysis, it is clear that hyperscaler-based data integration and MuleSoft-based integration should not be viewed as mutually exclusive, but rather as a hybrid model that works together. Serverless capabilities (in the context of compute, storage, and processing) and managed services provide numerous advantages and typically result in a great hybrid model between MuleSoft capabilities. Trying to fit a square peg into a round hole often complicates solutions that should be executed within guardrails such as cloud native, API first, and data virtualization. As a result, we believe that MuleSoft iPaaS should be used as the primary integration for real-time and non-complex data operations, with hyperscaler-based capabilities supplementing the gaps as mentioned above. This approach should be further strengthened by solid data governance tools, technologies, and practices (Data catalogs, glossary, Metadata management, Ontologies, Lineage, quality, and compliance.). It is also noted that the term “data layer” is broad, misleading, and it needs to be reconsidered in order to achieve cross-platform implementation synergy.
Cheers and Happy Building 🤘
