Building Modern Data Powerhouses
Considerations for building your Enterprise Data Ecosystems
An organization that seeks to get better at how they use data and AI will need to get their data architecture into shape. Assuming that you are going to be building your data platform on the cloud, you will find yourself trying to make the choice between BigQuery, Databricks, Snowflake, Dataproc, Redshift, Synapse, AWS, AZURE, GCP, etc. All of these are reasonable choices for building a data platform upon. Each vendor claims they are the best, and POCs and benchmarks are fraught with danger. In such situations, my suggestion is to go with a few guiding principles to choose the platform that is right for you.
Some considerations on my biases before reading this article:
- I have extensive experience with AWS and have been working with their application and data services close to a decade. It is a good allrounder.
- I believe that, within the realm of data and AI, it provides the most user-friendly, inventive, and seamlessly interconnected environment considering thier economy and fuel being data enables them to breed the best in class.
- Azure has come a long way to contend with its data suite, but I feel there are still a lot of missing features(integration, FGAC, RTP, query optimization..)
- I am taking a purely technical view here and not going deep into topics like data governance/management, authn/authz etc as it makes this very long..
- My primary focus will be on larger organizations with substantial operational experience and a broad market presence. As a developing organization, I recommend streamlining choices, standardizing processes, and emphasizing business functionalities. For larger enterprises with a significant cloud footprint, there exists an opportunity to harness the best-in-class and distinctive capabilities of various cloud services as needs arise. (To clarify, I’m not suggesting that larger organizations should disregard the mindset of smaller ones; rather, they might possess greater resources to establish a specialized ecosystem that leverages cutting-edge cloud capabilities for differentiation.)
User, Usage Driven Choices:
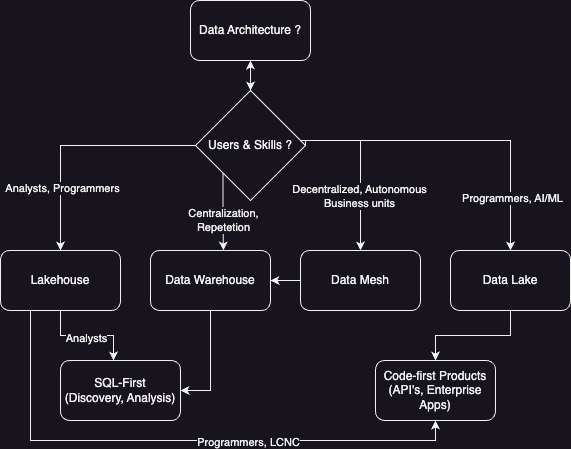
What is right Technology Architecture ?
Select your architecture based on your users skill sets, the nature of your workloads, any diffrenciating needs that your org may have(HCP, Access to Data and Inhouse research functions etc.):
-
A data warehouse functions as a SQL-centric data architecture, operating on data stored in a format specific to warehouses. Opt for this if your user base comprises primarily analysts rather than programmers—those capable of writing SQL or utilizing dashboard tools like Tableau, PowerBI, or Looker that generate SQL. It accommodates structured and semi-structured data, such as tabular and JSON data, but isn’t suitable for managing images, videos, or documents beyond storing their metadata. The key benefit of data warehouses lies in enabling self-service, on-the-fly querying by business users.
-
A data lake embodies a code-centric data architecture. Data resides in cloud storage (e.g., S3, GCS, ABS) and is accessed by job-specific or persistent compute clusters. Python/Spark is the prevalent programming language/framework, although Java and Scala are also commonly employed. Choose this approach if your user base consists mainly of programmers engaged in extensive data manipulation through code, including crafting ETL pipelines and training ML models. It supports unstructured data like images and videos but may be less efficient for structured and semi-structured data compared to a data warehouse. The primary advantage of data lakes lies in facilitating adaptable data processing by programmers.
-
A lakehouse combines features of both architectures to cater to both business users and programmers. It supports interactive queries and flexible data processing. It can be constructed in two ways: by making a data warehouse execute SQL on data stored in cloud storage (e.g., Parquet) or by using frameworks like SparkSQL for SQL operations on data lake storage. Both approaches involve compromises. A data warehouse using cloud storage sacrifices optimizations that render warehouses interactive and suitable for on-the-fly querying. A data lake running SQL sacrifices the schema-free data processing characteristic that grants data lakes flexibility. Thus, choose the hybrid architecture based on the user and workload types you aim to support exceptionally well versus those you’re willing to compromise on. This is the strategy or approach I would place my confidence in for the foreseeable future, particularly in 2023 and beyond.
-
A data mesh is primarily a philosophy and a set of guiding principles that can be flexibly applied as deemed suitable for an organization’s specific context and needs. It constitutes a decentralized data platform empowering each division within a company to manage its data while enabling data sharing without data movement. Establishing a data mesh might rely on agreeing upon a common data warehouse among divisions or building it around a data lake if consensus is lacking. In the latter scenario, due to varying user skill sets (SQL and Python) and workload requirements (interactive and adaptable data processing) across business units, each unit may opt for a distinct lakehouse implementation, which should be reserved for differentiating or niche reasons rather than merely adopting it without purpose. It’s essential to adhere to guiding principles, frameworks, and technologies unless there’s a compelling and solid reason to diverge from them.
-
Upon determining the data architecture, you’ve simultaneously decided whether a SQL-first data warehouse technology (e.g., Snowflake, BigQuery, Redshift, Synapse) or a Python-first data lake technology (e.g., Databricks, Dataproc, EMR) best suits your needs. The subsequent step involves selecting the specific SQL-first or Python-first product based on your requirements.
Operational, Organizational Considerations
-
For companies heavily invested in analytics/ML, a crucial decision involves choosing between decentralizing or standardizing their data platform. Organizations with greater agility and frequent M&A activity might find decentralization more practical(favouring mesh). Assess different business units within your company, considering varying user skill sets (SQL vs. Python) and workload preferences (interactive vs. flexible data processing). In such cases, granting each business unit the autonomy to select a fitting data platform implementation is advisable. Conversely, a top-down organizational structure favoring a single platform could yield higher cloud discounts and consistency, but at the expense of reduced business unit agility.
-
If opting for standardization, prioritize native cloud products. Using these products proves more cost-effective than platforms like Snowflake or Databricks, eliminating the burden of dual profit margins. As query volumes escalate, justifying the expense of an optimization team becomes feasible, resulting in cost savings. This holds particularly true for AWS and GCP.
-
In a decentralized approach, some units might prioritize usability and flexibility over cost. For instance, on AWS or Azure, business analyst teams may prefer Snowflake, while traditional data science (not machine learning) teams may opt for Databricks. On GCP, the native products often remain the most compelling choice.
-
It’s reasonable to select a different cloud for analytics/data science compared to applications. Despite potential egress cost friction and operating expenses of a second cloud, the enhanced ROI from a superior data platform might offset these costs. Should standardizing on a single cloud data platform be the goal, Google Cloud’s seamless integration between data products positions it as a strong contender. Unified governance, robust security across all data, and seamless connections between Spark, SQL, real-time, and transactional data accelerate development and manage costs effectively.
-
When considering cost efficiency on cloud, prioritize the use of native cloud products like Redshift or BigQuery over Snowflake or Databricks. The native cloud products generally prove more economical. Snowflake and Databricks often involve aggressive sales tactics, necessitating a more critical approach. Utilizing Snowflake on AWS means bearing the profit margins of both AWS (approximately 40-60%) and Snowflake (around 60-80%). Unless the native cloud product + opensource frameworks significantly underperforms, opting for it can lead to substantial cost savings. Snowflake may offer superior performance compared to Redshift or Bigquery, but the margin isn’t significant enough to justify the added cost.
-
In my personal experience for ease of use on AWS, Snowflake or Databricks may be preferred despite potentially higher operating costs. Managing Redshift demands considerable expertise in IAM and tuning, requiring a full-time engineer. When query volumes are relatively low, Snowflake might present a cost-effective option, especially when evaluating Snowflake’s Enterprise tier pricing. If the tuning demands for Redshift necessitate multiple engineers, it implies high query volumes, categorizing the organization as large-scale.
-
Consider that concerns about lock-in are irrelevant. A data platform itself results in a lock-in—either to a specific cloud platform (AWS, Azure, GCP) or vendor (Snowflake, Databricks). Fortunately, Spark is open-source, and SQL dialects across various data warehouses can be easily converted using tools like SQLglot. Hence, migration from one platform to another, if needed, is relatively straightforward.
Summarizing..
Select the data architecture primarily based on user skills and, secondarily, on whether interactivity or flexibility holds greater importance. This choice further directs toward a SQL-first or Python-first product. In the case of larger organizations, determine whether centralization or decentralization is more suitable. Centralization may favor GCP as the native cloud data & ML platform, while AWS native cloud products become preferable otherwise. Large organizations facing decentralization can empower individual business units to decide based on cost or ease-of-use, akin to smaller organizations. Regarding validation, the recommendations align with the general principles of leveraging native cloud solutions when feasible and making choices based on user skills and organizational needs. However, technology landscapes and best practices may evolve, necessitating periodic reassessment of platform choices for data architecture. For the latest and most specific recommendations, considering the current state of cloud platforms and data technologies is essential(remember these are changing drastically(inhouse engineering, aquisitions), Place your confidence in decisions guided by philosophy, steadfast commitment, and long-term sustainability. These aspects should form the foundation for making choices that endure and prosper over time.).
Cheers and Happy Building 🤘
